Inverse CDF Sampling
Inverse CDF sampling is a method for obtaining samples from both discrete and continuous probability distributions that requires the CDF to be invertible. The method assumes values of the CDF are Uniform random variables on . CDF values are generated and used as input into the inverted CDF to obtain samples with the distribution defined by the CDF.
Discrete Distributions
A discrete probability distribution consisting of a finite set of probability values is defined by,
with and . The CDF specifies the probability that and is given by,
For a given CDF value, , The equation for can always be inverted by evaluating it for each and searching for the smallest value of that satisfies, . It follows that generated samples determined from will have distribution since the intervals are uniformly sampled.
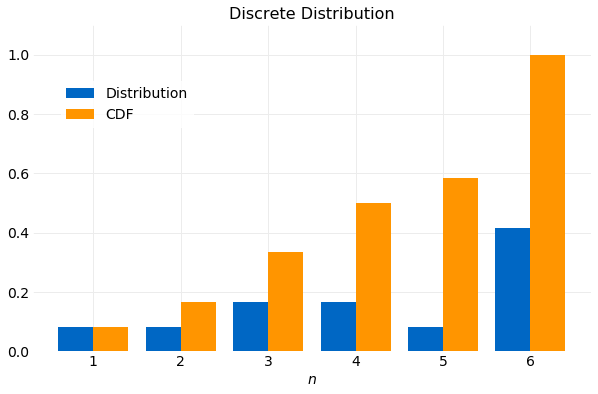
Consider the distribution,
It is shown in the following plot with its CDF. Note that the CDF is a monotonically increasing function.
A sampler using the Inverse CDF method with target distribution specified in implemented in Python is shown below.
import numpy
n = 10000
df = numpy.array([1/12, 1/12, 1/6, 1/6, 1/12, 5/12])
cdf = numpy.cumsum(df)
samples = [numpy.flatnonzero(cdf >= u)[0] for u in numpy.random.rand(n)]
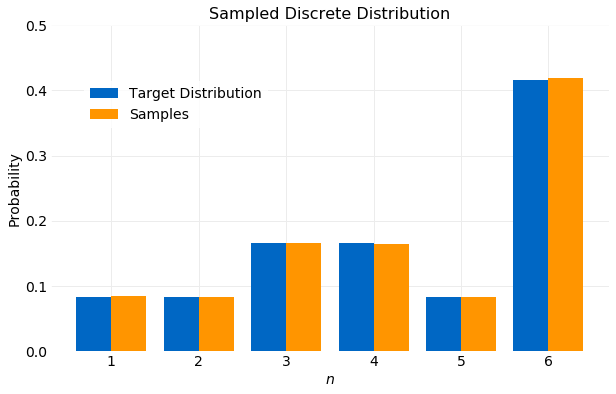
The program first stores the CDF computed from the partial sums in an array. Next, CDF samples using are generated. Finally, for each sampled CDF value, , the array containing is scanned for the smallest value of where . The resulting values of will have the target distribution . This is shown in the figure below.
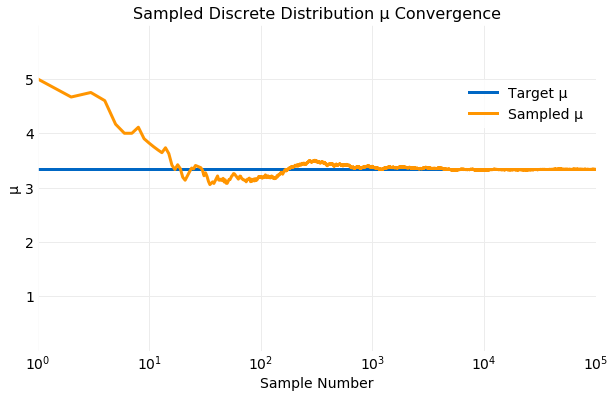
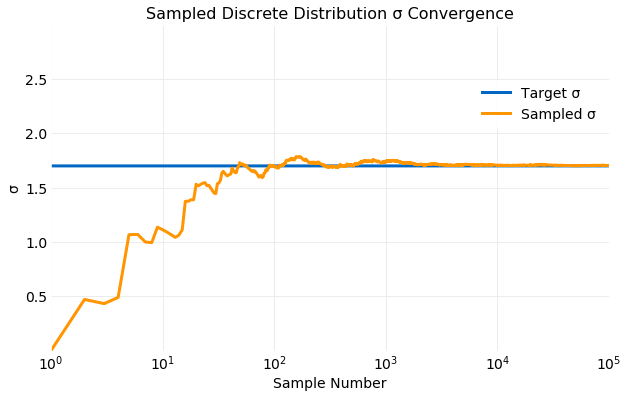
A measure of convergence of the samples to the target distribution can be obtained by comparing the cumulative moments of the distribution computed from the samples with the target value of the moment computed analytically. In general for a discrete distribution the first and second moments are given by,
In the following two plots the cumulative values of and computed from the samples generated are compared with the target values using the equations above. The first shows the convergence of and the second the convergence of . Within only samples both and computed from samples is comparable to the target value and by the values are indistinguishable.
The number of operations required for generating samples using Inverse CDF sampling from a discrete distribution will scale where is the desired number of samples and is the number of terms in the discrete distribution.
It is also possible to directly sample distribution using the multinomial sampler from numpy,
import numpy
n = 10000
df = numpy.array([1/12, 1/12, 1/6, 1/6, 1/12, 5/12])
samples = numpy.random.multinomial(n, df, size=1)/n
Continuous Distributions
A continuous probability distribution is defined by the PDF, , where and . The CDF is a monotonically increasing function that specifies the probability that , namely,
Theory
To prove that Inverse CDF sampling works for continuous distributions it must be shown that,
where is the inverse of and .
A more general result needed to complete this proof is obtained using a change of variable on a CDF. If is a monotonically increasing invertible function of it will be shown that,
To prove this note that is monotonically increasing so the ordering of values is preserved for all ,
Consequently, the order of the integration limits is maintained by the transformation. Further, since is invertible, and , so
where,
For completeness consider the case where is a monotonically decreasing invertible function of then,
it follows that,
The desired proof of equation follows from equation by noting that so ,
Example
Consider the Weibull Distribution. The PDF is given by,
where is the shape parameter and the scale parameter. The CDF is given by,
The CDF can be inverted to yield,
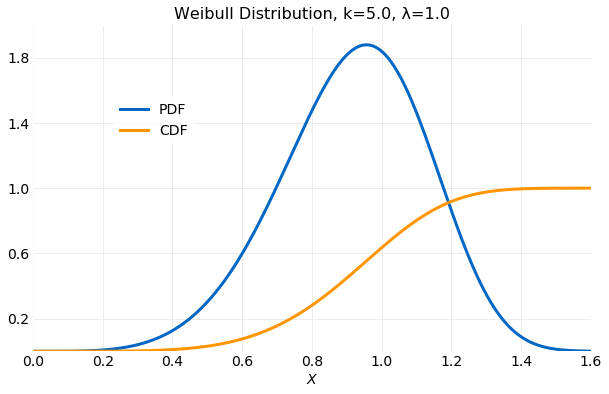
In the example described here it will be assumed that and . The following plot shows the PDF and CDF using these values.
The sampler implementation for the continuous case is simpler than for the discrete case. Just as in the discrete case CDF samples with distribution are generated. The desired samples with the target distribution are then computed using the CDF inverse. Below an implementation of this procedure in Python is given.
import numpy
k = 5.0
λ = 1.0
nsamples = 100000
cdf_inv = lambda u: λ * (numpy.log(1.0/(1.0 - u)))**(1.0/k)
samples = [cdf_inv(u) for u in numpy.random.rand(nsamples)]
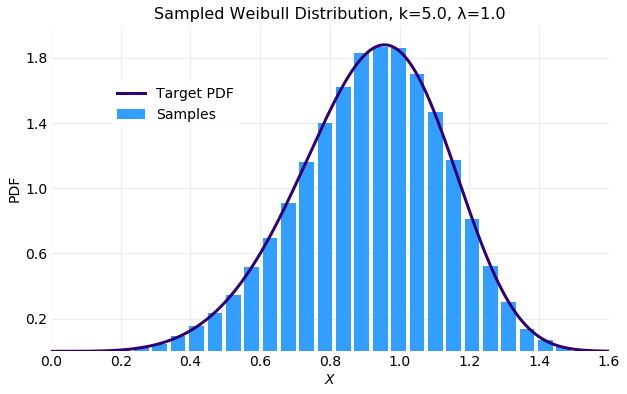
The following plot compares a histogram of the samples generated by the sampler above and the target distribution (5). The fit is quite good. The subtle asymmetry of the distribution is captured.
The first and second moments for the distribution are given by,
where is the Gamma function.
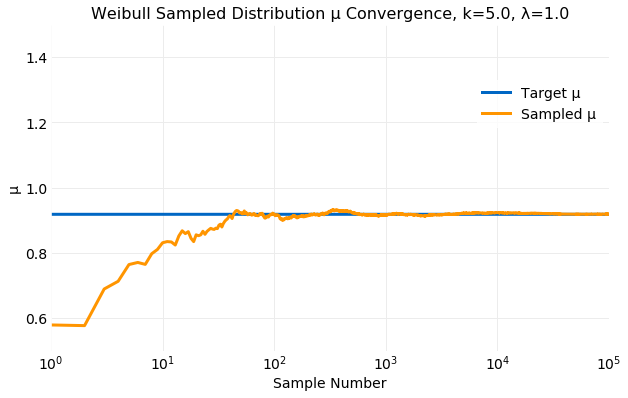
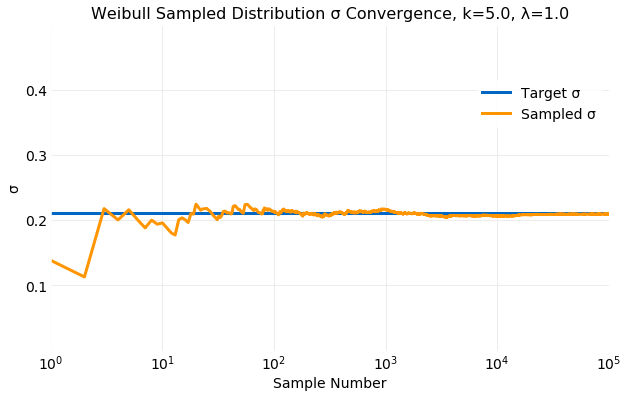
The following two plots compare the cumulative values of and computed from sampling of the target distribution with the values from the equations above. The first shows the convergence of and the second the convergence of . Within only samples both and computed from samples are comparable to the target values and by the values are indistinguishable.
Performance
Any continuous distribution can be sampled by assuming that can be approximated by the discrete distribution, for , where and . This method has disadvantages compared to using Inverse CDF sampling on the continuous distribution. First, a bounded range for the samples must be assumed when in general the range of the samples can be unbounded while the Inverse CDF method can sample an unbounded range. Second, the number of operations required for sampling a discrete distribution scales but sampling the continuous distribution is .
Conclusions
Inverse CDF Sampling provides a method for obtaining samples from a known target distribution using a sampler with a distribution that requires the target distribution be invertible. Algorithms for both the discrete and continuous cases were analytically proven to produce samples with distributions defined by the CDF. Example implementations of the algorithms for both distribution cases were developed. Samples produced by the algorithms for example target distributions were favorably compared. Mean and standard deviations computed from generated samples converged to the target distribution values in samples. The continuous sampling algorithm was shown to be more performant than the discrete version. The discrete version required operations while the continuous version required operations.