Rejection Sampling
Rejection Sampling is a method for obtaining samples for a known target probability distribution using samples from some other proposal distribution. It is a more general method than Inverse CDF Sampling which requires distribution to have an invertible CDF. Inverse CDF Sampling transforms a random variable into a random variable with a desired target distribution using the inverted CDF of the target distribution. While, Rejection Sampling is a method for transformation of random variables from arbitrary proposal distributions into a desired target distribution.
The implementation of Rejection Sampling requires the consideration of a target distribution, , a proposal distribution, , and a acceptance probability, , with distribution . A proposal sample, , is generated using, , and independently a uniform acceptance sample, , is generated using . A criterion is defined for acceptance of a sample, , to be considered a sample of ,
where, , is chosen to satisfy . If equation is satisfied the proposed sample is accepted as a sample of where . If equation is not satisfied is discarded.
The acceptance function is defined by,
It can be insightful to compare to when choosing a proposal distribution. If does not share sufficient mass with then the choice of should be reconsidered.
The Rejection Sampling algorithm can be summarized in the following steps that are repeated for the generation of each sample,
- Generate a sample .
- Generate a sample independent of .
- If equation is satisfied then is accepted as a sample of . If equation is not satisfied then is discarded.
Theory
To prove that Rejection Sampling works it must be shown that,
where is the CDF for ,
To prove equation a couple of intermediate steps are required. First, The joint distribution of and containing the acceptance constraint will be shown to be,
Since the Rejection Sampling algorithm as described in the previous section assumes that and are independent random variables, It follows that,
Next, it will be shown that,
This result follows from equation by taking the limit and noting that, .
Finally, equation can be proven, using the definition of Conditional Probability, equation and equation ,
Implementation
An implementation in Python of the Rejection Sampling algorithm is listed below,
def rejection_sample(h, y_samples, c):
nsamples = len(y_samples)
u = numpy.random.rand(nsamples)
accepted_mask = (u <= h(y_samples) / c)
return y_samples[accepted_mask]
The above function rejection_sample(h, y_samples, c) takes three arguments as input which are
described in the table below.
| Argument | Description |
|---|---|
h |
The acceptance function. Defined by . |
y_samples |
Array of samples of generated using . |
c |
A constant chosen so |
The execution of rejection_sample(h, y_samples, c) begins by generating an appropriate number of acceptance variable samples, , and
then determines which satisfy the acceptance criterion specified by equation (1). The accepted samples are then returned.
Examples
Consider the Distribution. The PDF is given by,
where is the shape parameter and the scale parameter. The CDF is given by,
The first and second moments are,
where is the Gamma function. In the examples described here it will be assumed that and . The plot below shows the PDF and CDF using these values.
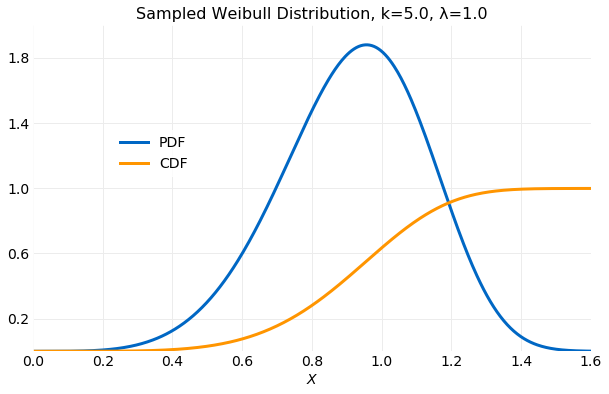
The following sections will compare the performance of generating samples using both and proposal distributions.
Uniform Proposal Distribution
Here a proposal distribution will be used to generate samples for the distribution . It provides a simple and illustrative example of the algorithm. The following plot shows the target distribution , the proposal distribution and the acceptance function used in this example. The uniform proposal distribution requires that a bound be placed on the proposal samples, which will be assumed to be . Since the proposal distribution is constant the acceptance function, , will be a constant multiple of the target distribution. This is illustrated in the plot below.
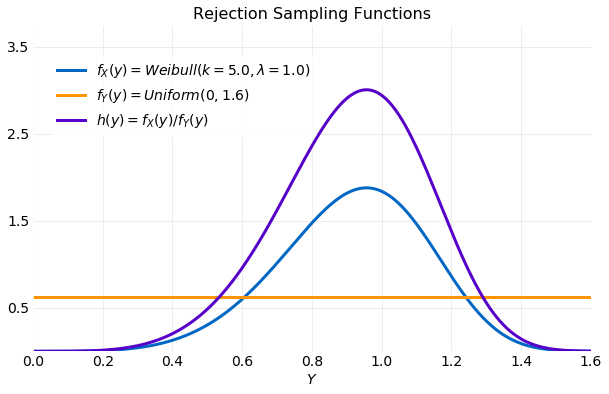
The Python code used to generate the samples using rejection_sample(h, y_samples, c) is listed
below.
weibull_pdf = lambda v: (k/λ)*(v/λ)**(k-1)*numpy.exp(-(v/λ)**k)
k = 5.0
λ = 1.0
xmax = 1.6
ymax = 2.0
nsamples = 100000
y_samples = numpy.random.rand(nsamples) * xmax
samples = rejection_sample(weibull_pdf, y_samples, ymax)
The following plot compares the histogram computed form the generated samples with the target distribution . The fit is acceptable.
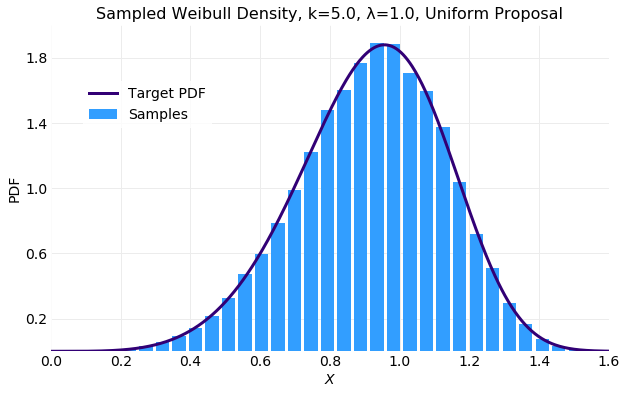
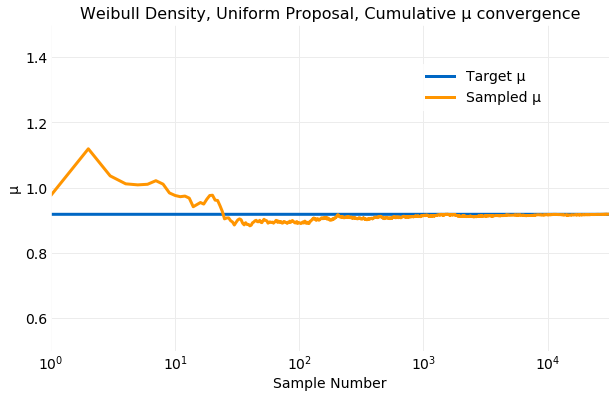
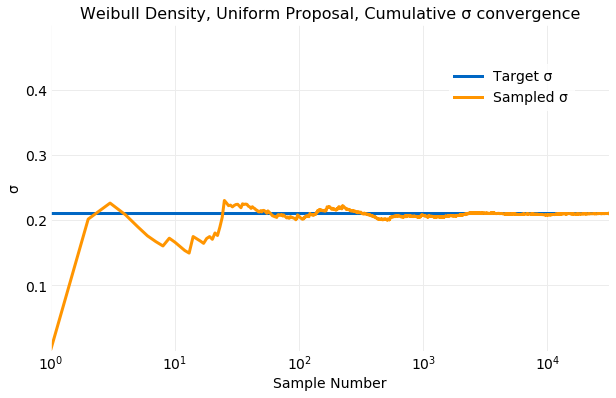
The next two plots illustrate convergence of the sample mean, , and standard deviation, , by comparing the cumulative sums computed from the samples to target distribution values computed from equation . The convergence of the sampled is quite rapid. Within only samples computed form the samples is very close the the target value and by samples the two values are indistinguishable. The convergence of the sampled to the target value is not as rapid as the convergence of the sampled but is still quick. By samples the two values are near indistinguishable.
Even though proposal samples were generated not all were accepted. The plot below provides insight into the efficiency of the algorithm. In the plot the generated pairs of acceptance probability and sample proposal are plotted with on the vertical axis and on the horizontal axis. Also, shown is the scaled acceptance function . If the sample is rejected and colored orange in the plot and if the sample is accepted, and colored blue. Only of the generated samples were accepted.
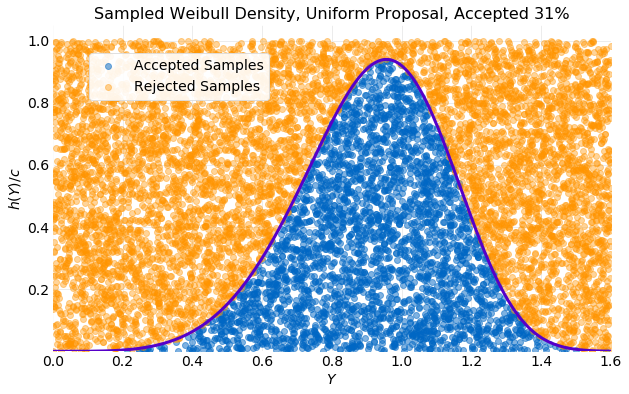
To improve the acceptance percentage of proposed samples a different proposal distribution must be considered. In the plot above it is seen that the proposal distribution uniformly samples the space enclosed by the rectangle it defines without consideration for the shape of the target distribution. The acceptance percentage will be determined by the ratio of the target distribution area enclosed by the proposal distribution and the proposal distribution area. As the target distribution becomes sharp the acceptance percentage will decrease. A proposal distribution that samples the area under efficiently will have a higher acceptance percentage. It should be kept in mind that rejection of proposal samples is required for the algorithm to work. If no proposal samples are rejected the proposal and target distributions will be equivalent.
Normal Proposal Distribution
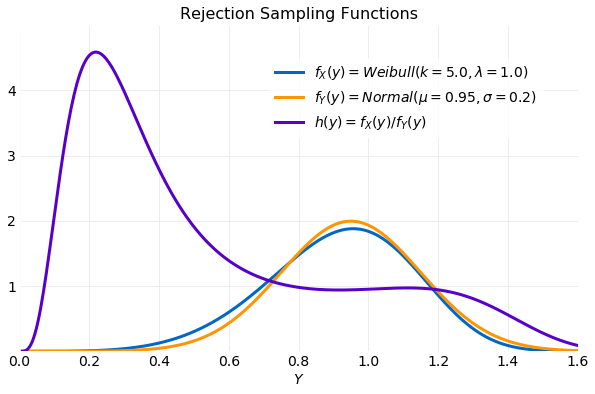
In this section a sampler using a proposal distribution and target distribution is discussed. A proposal distribution has advantages over the distribution discussed in the previous section. First, it can provide unbounded samples, while a uniform proposal requires specifying bounds on the samples. Second, it is a closer approximation to the target distribution so it should provide samples that are accepted with greater frequency. A disadvantage of the proposal distribution is that it requires specification of and . If these parameters are the slightest off the performance of the sampler will be severely degraded. To learn this lesson the first attempt will assume values for both the parameters that closely match the target distribution. The following plot compares the , the proposal distribution and the acceptance function . There is a large peak in to right caused by the more rapid increase of the distribution relative to the distribution with the result that most of its mass is not aligned with the target distribution.
The Python code used to generate the samples using rejection_sample(h, y_samples, c) is listed
below.
weibull_pdf = lambda v: (k/λ)*(v/λ)**(k-1)*numpy.exp(-(v/λ)**k)
def normal(μ, σ):
def f(x):
ε = (x - μ)**2/(2.0*σ**2)
return numpy.exp(-ε)/numpy.sqrt(2.0*numpy.pi*σ**2)
return f
k = 5.0
λ = 1.0
σ = 0.2
μ = 0.95
xmax = 1.6
nsamples = 100000
y_samples = numpy.random.normal(μ, σ, nsamples)
ymax = h(x_values).max()
h = lambda x: weibull_pdf(x) / normal(μ, σ)(x)
samples = rejection_sample(h, y_samples, ymax)
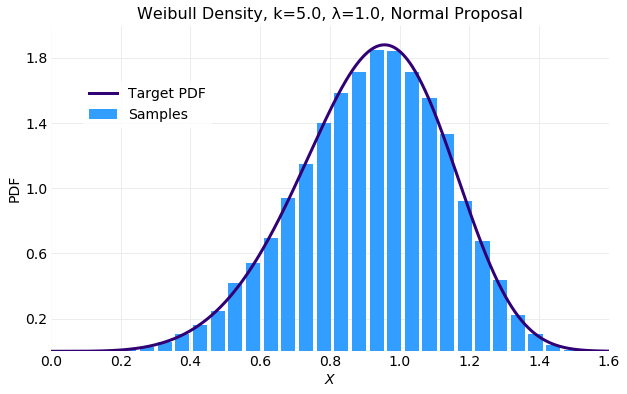
The first of the following plots compares the histogram computed from the generated samples with the target distribution and the second illustrates which proposal samples were accepted. The histogram fit is good but only of the samples were accepted which is worse than the result obtained with the uniform proposal previously discussed.
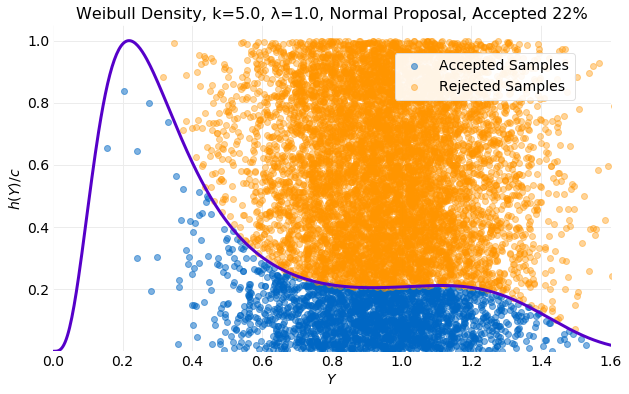
In an attempt to improve the acceptance rate of the proposal distribution is decreased slightly and is increased. The result is shown in the next plot. The proposal distribution now covers the target distribution tails. The acceptance function, , now has its peak inside the target distribution with significant overlap of mass.
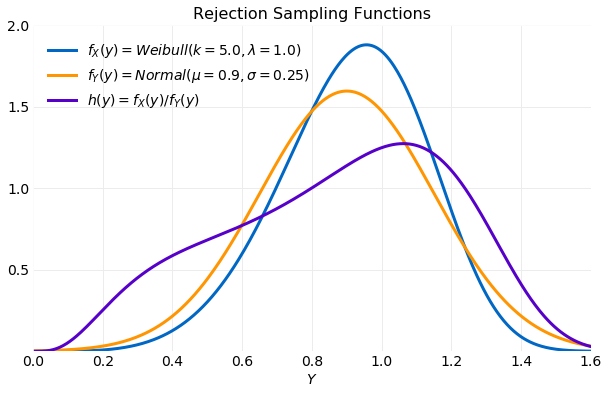
The result is much improved. In the plot below it is seen that the percentage of accepted samples has increased to .
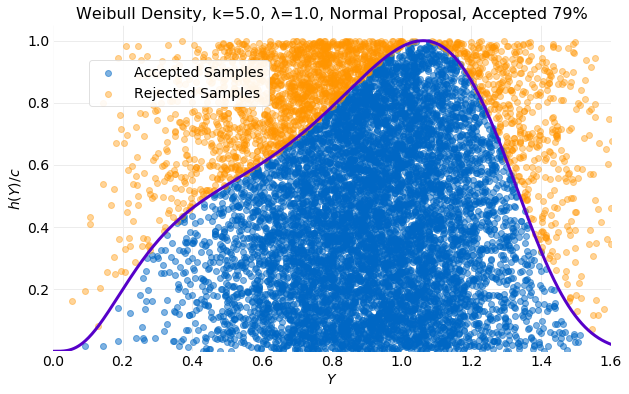
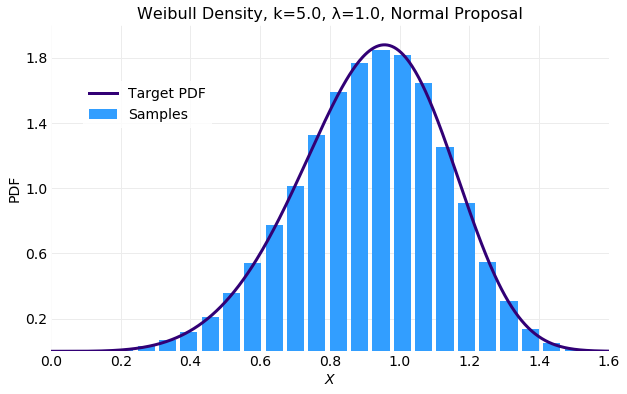
The first of the plots below compares the histogram computed from generated samples with the target distribution and next two compare the cumulative values of and computed from the generated samples with the target distribution values from equation . The histogram is the best fit of the examples discussed here and convergence of the sampled and occurs in about samples.
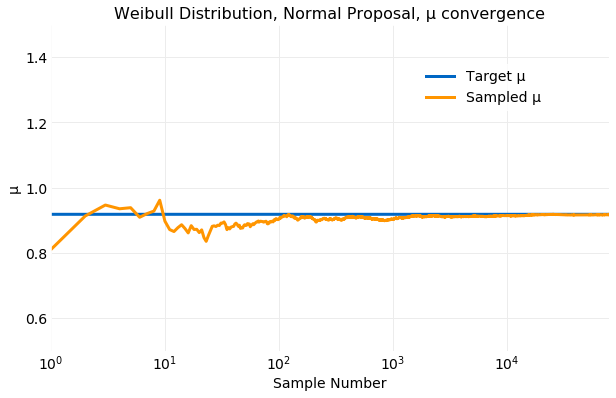
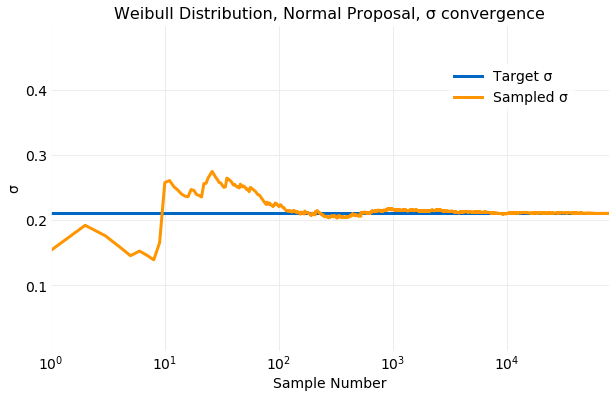
Sampling the distribution with a proposal distribution can produce a better result than a uniform distribution but care must be exercised in selecting the distribution parameters. Some choices can produce inferior results. Analysis of the the acceptance function can provide guidance in parameter selection.
Conclusions
Rejection Sampling provides a general method for generation of samples for a known target distribution by rejecting or accepting samples from a known proposal distribution sampler. It was analytically proven that if proposal samples are accepted with a probability defined by equation the accepted samples have the desired target distribution. An algorithm implementation was discussed and used in examples where its performance in producing samples with a desired target distribution for several different proposal distributions was investigated. Mean and standard deviations computed from generated samples converged to the target distribution values in samples.for both the discrete and continuous cases. It was shown that the performance of the algorithm can vary significantly with chosen parameter values for the proposal distribution. A criteria for evaluating the expected performance of a proposal distribution using the acceptance function, defined by equation , was suggested. Performance was shown to improve if the acceptance function has significant overlap with the proposal distribution.