A Markov Chain is a sequence of states
where transitions between states occur ordered in time with
the probability of transition depending only on the previous state. Here the
states will be assumed a continuous unbounded set and time a discrete unbounded set. If the
set of states is given by, x∈R, the probability that the process
will be in state x at time t, denoted by
πt(y), is referred to as the distribution. Markov Chain equilibrium is
defined by limt→∞πt(y)<∞, that is, as time advances
πt(y) becomes independent of time. Here a solution
for this limit is discussed and illustrated with examples.
Model
The Markov Chain is constructed from the set of states {x},
ordered in time, where x∈R.
The process starts at time t=0 with state X0=x.
At the next step, t=1, the process will assume a state
X1=y, y∈{x},
with probability P(X1=y∣X0=x)
since it will depend on the state at t=0 by the definition of a Markov Process.
At the next time step t=2 the process state will be
X2=z,wherez∈{x} with probability,
P(X2=z∣X0=x,X1=y)=P(X2=z∣X1=y),
since by definition the probability of state transition depends only upon the state at the previous time step.
For an arbitrary time the transition from a state Xt=x to a state
Xt+1=y will occur with probability, P(Xt+1=y∣Xt=x)
that is independent of t.
The Transition Kernel,
defined by,
p(x,y)=P(Xt+1=y∣Xt=x),
plays the same role as the transition matrix plays in the theory of
Discrete State Markov Chains. In general p(x,y) cannot always be represented by a probability density function, but
here it is assumed that it has a density function representation.
This leads to the interpretation that for a known value of xp(x,y) can be interpreted as a conditional probability density for a transition to state y given that the process is in state x, namely,
p(x,y)=f(y∣x)
Consequently, p(x,y) is a family of conditional probability distributions each
representing conditioning on a possible state of the chain at time step t.
Since p(x,y) is a conditional probability density for each value of
x it follows that,
∫−∞∞p(x,y)dy=1∀xp(x,y)≥0∀x,y(1).
The transition kernel for a single step in the Markov Process is defined by p(x,y). The
transition kernel across two time steps is computed as follows. Begin by denoting the process state at time
t by Xt=x, the state at t+1 by
Xt+1=y and the state at t+2 by
Xt+2=z. Then the probability of transitioning to a state
Xt+3=z from Xt=x in two steps,
p2(x,z), is given by,
f(z∣x)=∫−∞∞f(z∣x,y)f(y∣x)dy=∫−∞∞f(z∣y)f(y∣x)dy=∫−∞∞p(y,z)p(x,y)dy=∫−∞∞p(x,y)p(y,z)dy
where use was made of the Law of Total Probability, in the
first step and second step used the Markov Chain property f(z∣x,y)=f(z∣y).
Now, the result obtained for the two step transition kernel is the continuous version of
matrix multiplication of the single step transitions probabilities.
A operator inspired by matrix multiplication would be helpful. Make the definition,
P2(x,z)=∫−∞∞p(x,y)p(y,z)dy.
Using this operator, with Xt+3=w, the three step transition kernel is given by,
f(w∣x)=∫−∞∞f(w∣x,z)f(z∣x)dz=∫−∞∞f(w∣z)[∫−∞∞f(z∣y)f(y∣x)dy]dz=∫−∞∞∫−∞∞f(w∣z)f(z∣y)f(y∣x)dydz=∫−∞∞∫−∞∞p(z,w)p(y,z)p(x,y)dydz=∫−∞∞∫−∞∞p(x,y)p(y,z)p(z,w)dydz=P3(x,w),
where the second step substitutes the two step transition kernel and the remaining steps perform the decomposition to the single step transition kernel, p(x,y). Use of
Mathematical Induction is used to show that the transition
kernel between two states in an arbitrary number of steps, t, is given by,
The distribution of Markov Chain states π(x) is defined by,
∫−∞∞π(x)dx=1π(x)≥0∀x
To determine the equilibrium distribution, πE(x), the time
variability of πt(x) must be determined. Begin by considering an arbitrary
distribution at t=0, π0(x). The distribution
after the first step will be,
Thus equation (4) defines the time invariant solution to equation
(3).
To go further a particular form for the transition kernel must be specified. Unlike the
discrete state model
a general solution cannot be obtained since convergence of the limit t→∞ will
depend on the assumed transition kernel. The following section will describe a solution to equation
(4) arising from a simple stochastic processes.
Example
To evaluate the equilibrium distribution a form for the transition kernel must be assumed. Here the
AR(1) stochastic process is considered.
AR(1) is a simple first order autoregressive model providing an example of a continuous state Markov Chain.
In following sections its equilibrium distribution is determined and the results of simulations are discussed.
AR(1) is defined by the difference equation,
Xt=αXt−1+εt(5),
where t=0,1,2,… and the εt are identically
distributed independent Normal
random variables with zero mean and variance, σ2. The t
subscript on ε indicates that it is generated at time step
t.
The transition kernel for AR(1) can be derived from equation (5) by using,
εt∼Normal(0,σ2) and letting
x=xt−1 and y=xt so that
εt=y−αx. The result is,
p(x,y)=2πσ21e−(y−αx)2/2σ2(6)
Now, consider a few steps,
X1X2X3=αX0+ε1=αX1+ε2=αX2+ε3,
substituting the first equation into the second equation and that result into the third equation gives,
X3=α3X0+α2ε1+αε2+ε3
If this process is continued for t steps the following result is
obtained,
Xt=αtX0+i=1∑tαt−iεi(7).
Equilibrium Solution
In this section equation (7) is used to evaluate the the mean and variance of
the AR(1) process in the equilibrium limit t→∞. The mean and variance
obtained are then used to construct πE(x) that is shown to be a solution
to equation (4).
The last step follows from summation of a geometric series,
i=1∑t(α2)t−1=k=0∑t−1(α2)k=1−α21−(α2)t−1.
In the limit t→∞E(Xt2) only converges for ∣α∣<1. If α=1 the denominator of the second term in
of E(Xt2) is 0E(Xt2) is
undefined. σE2
is evaluated assuming ∣α∣<1 if this is the case
(8) gives μE=0, so,
The equilibrium distribution, πE, is found by substituting the results
from equation (8) and (9) into a
Normal(μE,σE2) distribution to obtain,
πE(y)=2πσE21e−y2/2σE2(10)
It can be shown that equation (10) is the equilibrium distribution by verifying that it is a solution to
equation (4). Inserting equations (6) and
(10) into equation (4) yields,
An AR(1) simulator can be implemented using either the difference equation definition, equation
(5) or the transition kernel, equation (6).
The result produced by either are statistically identical, An example implementation in Python using
equation (5) is shown below.
The function ar_1_difference_series(α, σ, x0, nsamples) takes four arguments: α and σ, the initial value
of x, x0 and the number of desired samples nsample. It begins by allocating storage
for the sample output followed by generation of nsample values of ε∼Normal(0,σ2) with the requested standard deviation, σ. The samples are then created using the AR(1 ) difference equation, equation (5).
A second implementation using the transition kernel, equation (6) is shown below.
The function ar1_kernel_series(α, σ, x0, nsamples) also takes four arguments: α and σ
from equation (6),
the initial value of x, x0 and the number of desired samples, nsample.
It begins by allocating storage for the sample output and then generates samples using the transition kernel
with distribution Normal(α∗samples[i−1],σ2).
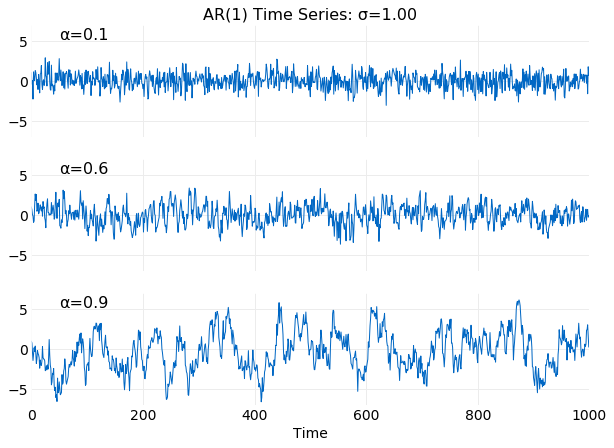
The plots below show examples of time series generated
using ar_1_difference_series with σ=1 and values of α
satisfying α<1. It is seen that for smaller α values of
the series more frequently change direction and have smaller variance. This is expected from
equation (9), where σE=1/1−α2.
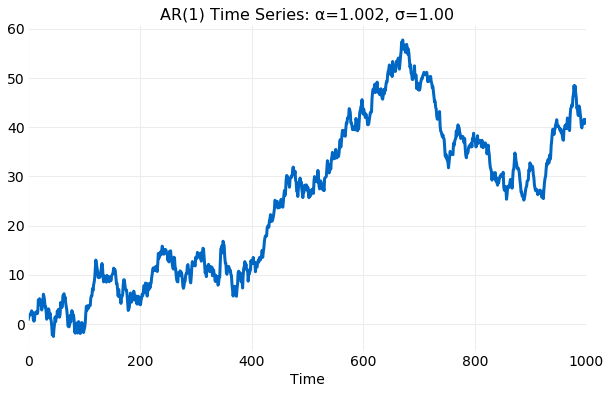
If α is just slightly larger than 1 the time series
can increase rapidly as illustrated in the plot below.
For α<1σE is bounded and the generated
samples are constrained about the equilibrium mean value, μE=0, but for
α≥1σE is unbounded
and the samples very quickly develop very large deviations from μE.
Convergence to Equilibrium
For sufficiently large times samples generated by the AR(1) process will approach the equilibrium values
for α<1. In the plots following the cumulative values of both the
mean and standard deviation computed from simulations, using ar_1_difference_series with
σ=1, are compared with the equilibrium vales μE
and σE from equations (8) and
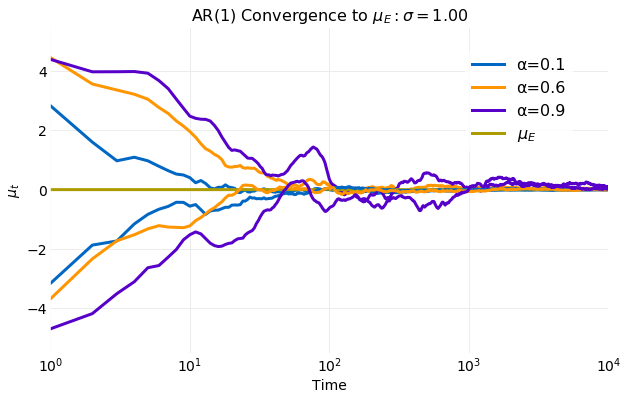
(9) respectively. The first plot illustrates the convergence μ
to μE for six different simulations with varying initial states,
X0, and α. The rate of convergence is seen to
decrease as α increases. For smaller α the simulation
μ is close to μE within 102
samples and indistinguishable from μE by 103. For larger
values of α the convergence is mush slower. After 105
samples there are still noticeable oscillations of the sampled μ about
μE.
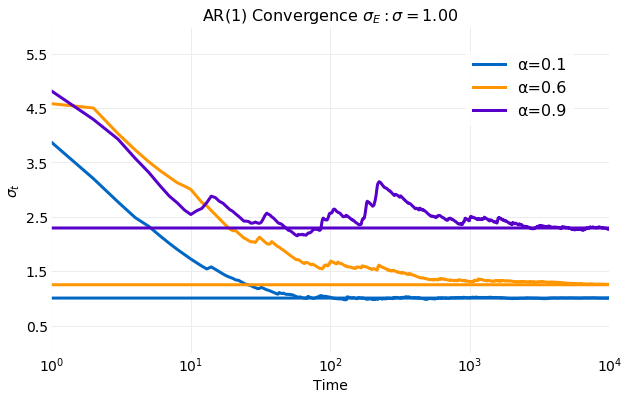
Since σE varies with α for clarity only simulations
with varying α are shown. The rate of convergence σ to
σE is slightly slower than the rate seem for μ. For
smaller α simulation σ computations are
indistinguishable form σE by 103 samples. For larger
α after 104 sample deviations about the
σE are still visible.
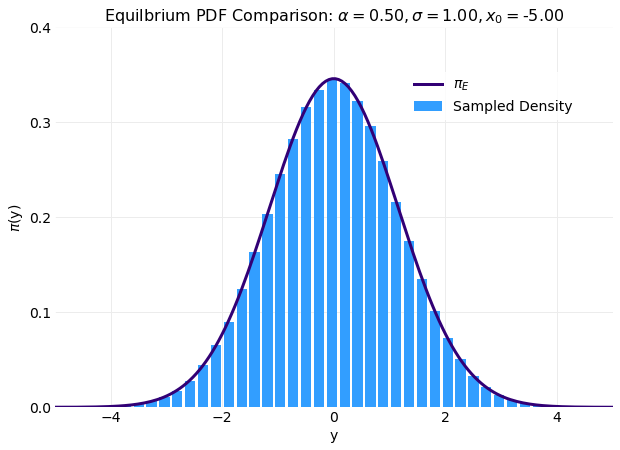
The plot below favorably compares the histogram produced from results of a simulation of 106
samples and the equilibrium distribution, πE(y), from equation (10).
A more efficient method of estimating πE(y) is obtained from equation
(4) by noting that for sufficiently large number of samples equation
(4) can be approximated by the expectation of the transition kernel, namely,
The first function ar_1_kernel(α, σ, x, y) computes the transition kernel for a range of values and takes four arguments as
input: α and σ from equation (5) and the value of x and an array of y values where
the transition kernel is evaluated. The second function ar_1_equilibrium_distributions(α, σ, x0, y, nsample) has five arguments as input: α and σ, the initial value of x, x0, the array of y values used to evaluate the transition kernel and
the number of desired samples nsample. ar_1_equilibrium_distributions begins by calling ar_1_difference_series to generate
nsample samples of x. These values and the needed inputs are then passed to ar_1_kernel providing nsample evaluations of
the transition kernel. The cumulative average of the transition kernel is then evaluated and returned.
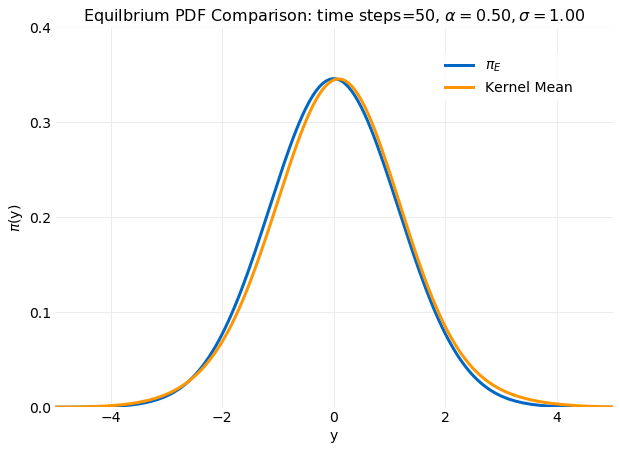
In practice this method gives reasonable results for as few as 102 samples. This is illustrated
in the following plot where the transition kernel mean value computed with just 50 samples
using ar_1_equilibrium_distributions is compared πE(y) from equation
(10).
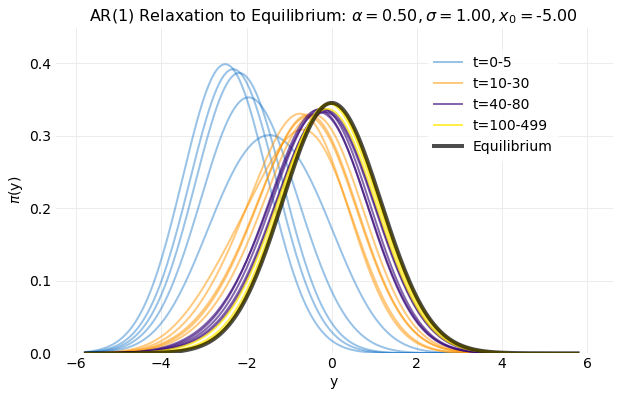
The following plot shows intermediate values the calculation in the range of 1 to
50 samples. This illustrates the changes in the estimated equilibrium distribution
as the calculation progresses. By 500 samples a distribution near the equilibrium distribution
is obtained.
Conclusions
Markov Chain equilibrium for continuous state processes provides a general theory of the time evolution
of stochastic kernels and distributions. Unlike the case for the discrete state model general solutions cannot be obtained
since evaluation of the obtained equations depends of the form of the stochastic kernel. Kernels will
exist which do not have equilibrium solutions. A continuous state process that has an equilibrium
distribution that can be analytically evaluated is AR(1). The stochastic kernel for AR(1) is derived
from its difference equation representation and the first and second moments are evaluated in
the equilibrium limit, t→∞. It is shown that finite values exists only
for values of the AR(1) parameter that satisfy ∣α∣<1.
A distribution is then constructed using these moments and shown to be the equilibrium distribution.
Simulations are performed using the difference equation
representation of the process and compared with the equilibrium calculations. The rate of convergence
of simulations to the equilibrium is shown to depend on α. For values
not near 1 convergence of the mean occurs with O(103)
time steps and convergence of the standard deviation with O(104) time steps.
For values of α closer to 1 convergence has
not occurred by 104 time steps.