Metropolis Hastings Sampling
Metropolis Hastings Sampling is a method for obtaining samples for a known target
probability distribution using samples from some other proposal distribution. It is similar to
Rejection Sampling in providing a
criteria for acceptance of a proposal sample as a target sample but instead of discarding the
samples that do not meet the acceptance criteria the sample
from the previous time step is replicated. Another difference is that Metropolis Hastings samples are modeled as a Markov Chain where the target distribution
is the
Markov Chain Equilibrium Distribution.
As a consequence
the previous sample is used as part of the acceptance criteria when generating the next sample.
It will be seen this has the advantage of permitting adjustment of some proposal distribution
parameters as each sample is generated, which in effect eliminates parameter inputs.
This is is an improvement over Rejection Sampling, where it was
previously shown that
slight variations in proposal distribution parameters can significantly impact performance.
A downside of the Markov Chain representation is that
autocorrelation can develop in the samples
which is not the case in Rejection Sampling.
Algorithm
The Metropolis Sampling Algorithm was developed by physicist studying simulations of equation of state at the dawn of the computer age.
It is the first a a class of sampling algorithms referred to a Monte Carlo Markov Chain.
A couple of decades later the algorithm was generalized and given a firmer theoretical foundation becoming the Metropolis Hastings Sampling Algorithm.
After a few more decades this work became widely used in simulating Bayesian Posterior Distributions
in Probabilistic Programming DSLs such as pymc. This section provides an overview of the algorithm
to motivate details of the theory and examples discussed in following sections.
Let denote the target distribution. The algorithm constructs a Markov Chain with equilibrium distribution, , such that,
The equilibrium stochastic kernel, , for the Markov Chain must satisfy,
To generate samples for samples from a proposal Markov Chain with stochastic kernel are produced. Let denote the state of the Markov Chain at the previous time step, , and represent the yet to be determined state at time . Consider a proposal sample, , generated by . Define an acceptance function, , that satisfies,
and an acceptance random variable, , with distribution independent of . Now, if the following inequality is satisfied,
accept the proposed sample, , as a sample of . If the inequality is not satisfied then reject the sample by replicating the state from the previous time step, .
It will be shown that,
The algorithm can be summarized by the following steps that are repeated for each sample.
- Generate samples of conditioned on and independently generate samples of .
- If then .
- If then .
Theory
Metropolis Hastings Sampling is simple to implement but the theory that provides validation of the algorithm is more complicated than required for both Rejection Sampling and Inverse CDF Sampling. Here the proof that the algorithm produces the desired result is accomplished in four steps. The first will show that distributions and stochastic kernels that satisfy Time Reversal Symmetry, also referred to as Detailed Balance, are equilibrium solutions that satisfy equation Next, the stochastic kernel resulting from the algorithm is derived and followed by a proof that a distribution that satisfies Time Reversal Symmetry with the resulting stochastic kernel is a solution to equation Finally, the expression for from equation will be derived.
Time Reversal Symmetry
Consider a stochastic kernel and distribution where is the state of the Markov Chain generated by the kernel at and the state at time . If the chain has steps the expected number of transitions from to will satisfy,
It follows that the rate of transition from to is given by . The transition rate for the Markov Chain obtained by reversing time, that is the chain transitions from to will be .
Time Reversal Symmetry implies that the transition rate for the time reversed Markov Chain is the same as the forward time chain,
If Time Reversal Symmetry is assumed it follows that,
where the last step is a result of the definition of a stochastic kernel, . Thus any distribution and kernel satisfying equation is an equilibrium solution since it will also satisfy equation
Stochastic Kernel
In a previous post it was shown that a stochastic kernel can be interpreted as probability density conditioned of the state at the previous time step,
It follows that the Cumulative Probability Distribution (CDF) of obtaining a sample for a given is given by,
Let represent the acceptance random variable. A proposal sample, conditioned on , is generated by independent of and accepted if,
then . The proposal is rejected if,
then . Now, using the Law of Total Probability to condition on the stochastic kernel CDF becomes,
The first term is the probability that the proposed sample is accepted and the second term the probability that it is rejected. Consider the first term where and ,
which follows from the definition of Conditional Probability.
The algorithm assumes that is independent of conditioned on . It follows that the joint density is given by,
where the last step follows by noting that since the density of is given by and the density of conditioned on is given by the proposal stochastic kernel, Using this result to continue gives the acceptance probability term for the stochastic kernel CDF from equation ,
Next, consider the second term in equation , which represents the case where is rejected as a sample of . Since is rejected . It follows that any value of is possible so the integral over needs to be over its entire range. Using the previous result for the joint density . gives
since . Simplify things by defining the rejection probability density by,
Equation needs to be written as an integral over to continue with the evaluation of equation . This is accomplished by use of the Dirac Delta Function which is defined by,
If use is made of equation and the Dirac Delta Function it follows that equation becomes,
The upper range of the limit was changed to conform to the limits of the CDF. This is acceptable since if the probability of rejection is 0. The Metropolis Hastings stochastic kernel can now by constructed by assembling the results obtained in equations and and revisiting equation ,
Finally, the desired result is obtained by collecting the terms under a single integration variable,
Verify that the kernel satisfies the stochastic property,
which is the desired result.
Equilibrium
It can now be shown that the Metropolis Hastings stochastic kernel from equation is an equilibrium solution by evaluating the integral from equation that defines equilibrium. Additionally, Time Reversal Symmetry must also be assumed,
where is the acceptance function from equation , is the stochastic kernel for the proposal Markov Chain, is the distribution, is the state of the target Markov Chain at time step and the state at time .
Now, starting with equation ,
where the last steps follow from substituting equation into the last term leading to the desired result.
Derivation of
It has been shown that the Metropolis Hastings algorithm generates a Markov Chain with an equilibrium distribution equal to the target distribution. This has been accomplished by only requiring that the acceptance function, , satisfy Time Reversal Symmetry as specified by equation without giving and explicit form. Here an expression for is derived with the aim of driving arbitrary proposal Markov Chains toward states satisfying Time Reversal Symmetry.
For an arbitrary proposal stochastic kernel, , Time Reversal Symmetry will not be satisfied, so either or will be true. Assume the first condition is valid. If this is the case transitions from to occur more frequently than transitions from to . To correct for the imbalance the number of transitions from to needs to be decreased and the number of transition from to increased. This can be accomplished by setting in equation to obtain,
Solving this equation for gives,
Similarly if the second condition, , is satisfied by the proposal stochastic kernel the number of transitions from to needs to be increased and the transitions from to decreased. Setting in equation produces the desired result,
Solving for gives,
which is the time reversed version of the first result. Equation follows when the constraint, is considered,
Example
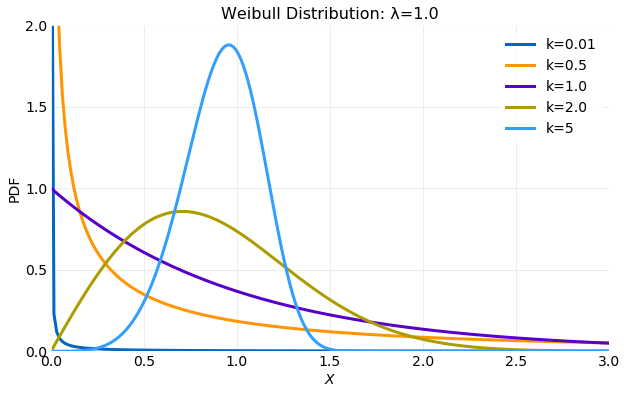
Here an example implementation of the Metropolis Hastings Sampling algorithm using a target distribution and proposal distribution is discussed. The distribution PDF is defined by,
where is the shape parameter and the scale parameter. The first and second moments are,
where is the Gamma function. The following plot illustrates the variation in the distribution for a fixed value of the scale parameter of as the shape parameter, , is varied. The following sections will assume that and .
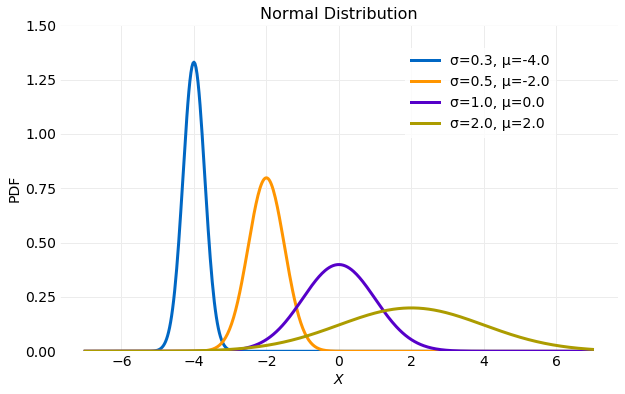
The Normal distribution is defined by the PDF,
where is the location parameter and first moment and is the scale parameter and second moment. The following plot illustrates variation in the PDF as the scale and location parameter are varied.
Proposal Distribution Stochastic Kernel
The Metropolis Hastings Sampling algorithm requires a stochastic kernel based on the proposal distribution. A stochastic kernel can be derived from the difference equation,
where and the are identically distributed independent random variables with zero mean and variance, . Let and then the equation above becomes,
Substitution into equation gives the stochastic kernel,
The form of is a distribution with
mean . This has eliminated as a free parameter.
The only arbitrary parameter is the standard deviation, . In
the implementation will be referred to as the stepsize. The plot below
shows how varies with each step in a simulation. The first five steps
are shown for an initial condition and stepsize=1.0.
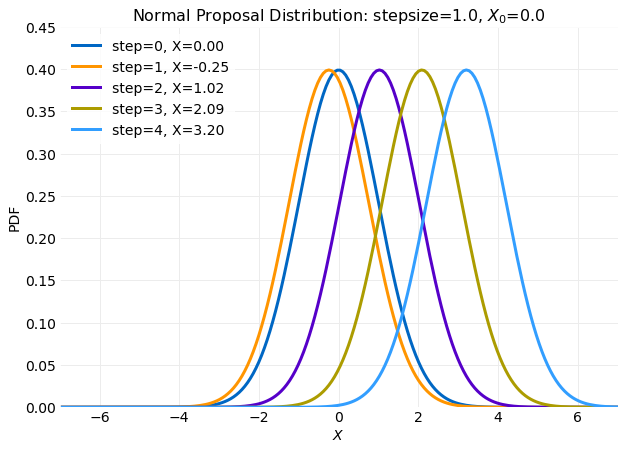
In the plot it is seen that the distribution is recentered at each step about the the previous value. This behavior is a consequence of the assuming a proposal distribution. Using another form for a proposal distribution could use a different parameterization.
A Rejection Sampling implementation using the same proposal and target distributions has both and as arbitrary parameters. Modeling the sampling process as a Markov Chain has eliminated one parameter.
Implementation
Metropolis Hastings Sampling is simple to implement. This section will describe an implementation
in Python using libraries available in numpy. Below a sampler for
using the numpy normal random number generator is shown.
import numpy
def qsample(x, stepsize):
return numpy.random.normal(x, stepsize)
qsample(x, stepsize) takes two arguments as input. The first is x, the previous state, and
the second the stepsize. x is used as the loc parameter and stepsize the scale parameter
in the call to the numpy normal random number generator.
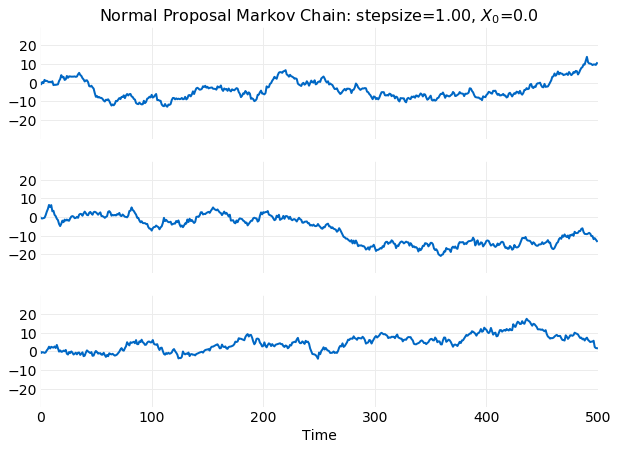
Simulations of time series using qsample(x, stepsize) can be performed using the code below.
stepsize = 1.0
x0 = 0.0
nsamples = 500
x = numpy.zero(nsamples)
x[0] = x0
for j in range(1, nsamples):
x[j] = qsample(x[j-1], stepsize)
The following plot shows time series generated by three separate runs of the code listed above.
The Python implementation of the algorithm summarized in the Algorithm section is shown below,
def metropolis_hastings(f, q, qsample, stepsize, nsample, x0):
x = x0
samples = numpy.zeros(nsample)
for i in range(nsample):
u = numpy.random.rand()
y_star = qsample(x, stepsize)
fy_star = f(y_star)
fx = p(x)
α = (fy_star*q(y_star, x, stepsize)) / (fx*q(x, y_star, stepsize))
if u < α:
x = y_star
samples[i] = x
return samples
metropolis_hastings(f, q, qsample, stepsize, nsample, x0) takes five arguments as input that are
described in the table below.
| Argument | Description |
|---|---|
f |
The target distribution which is assumed to support an interface taking a the previous state, x, as a floating point argument. In this example equation is used. |
q |
The proposal stochastic kernel which is assumed to support an interface taking the previous state, x, and the stepsize both as floating point arguments. In this example equation is used. |
qsample |
A random number generator based on the proposal stochastic kernel, It is assumed to support an interface taking the previous state, x, and the stepsize both as floating point arguments. The implementation used in this example is the function qsample(x, stepsize) previously discussed. |
stepsize |
The scale parameter used by the proposal distribution. |
nsample |
The number of samples desired. |
x0 |
The initial target sample value. |
The execution of metropolis_hastings(f, q, qsample, stepsize, nsample, x0) begins by allocation of storage for
the result and initialization of the Markov Chain. A loop is then executed nsample times
where each iteration generates the next sample. Within the loop the acceptance random variable
with distribution is generated using the numpy random number
generator. Next, a proposal sample is generated using qsample(x, stepsize) followed by evaluation
of the acceptance function . Finally, the acceptance criteria is
evaluated leading the sample being rejected or accepted.
Simulations
Here the results of simulations performed using,
metropolis_hastings(f, q, qsample, stepsize, nsample, x0),
from the previous section are discussed. The simulations assume the
target distribution
from equation with and
and the stochastic kernel from
equation . First, simulations that scan 4 orders of magnitude of stepsize
with x0 fixed are compared with the goal of determining the value leading to the best performance.
Next, simulations are performed with stepsize fixed that scan values of x0 to determine the impact
of initial condition on performance. Finally, a method for removing autocorrelation from generated samples using Thinning is discussed.
The criteria for evaluating simulations include the time for
convergence of the first and seconds moments computed from samples to the target
distribution moments, the fit of the sampled distribution to the target PDF, the percentage of
accepted proposal samples and the timescale for the decay of time series autocorrelation.
It will be shown that stepsize is the only relevant parameter. The choice for x0 will be seen
to have an impact that vanishes given sufficient time. Thus, the model has a single parameter of significance.
Performance
The plot below shows the percentage of proposal samples accepted as a function of stepsize for
simulations with stepsize ranging from to .
For all simulations x0=1.0. The simulation believed to be the best performing accepted
of the proposed samples and had a stepsize of . The two other simulations discussed
in this section as representative of small and large values of stepsize had acceptance
percentages of and for stepsize values of
and respectively. Each of this simulations is indicated in the plot below.
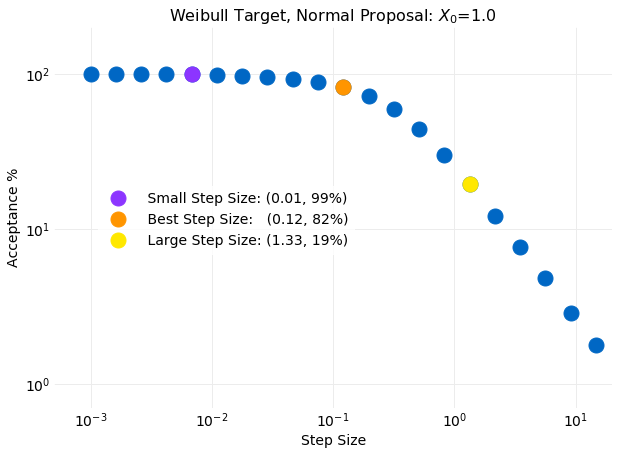
On examination of the plot it is seen that for stepsize smaller than
, the simulations to the left of the orange symbol, the accepted percentage of
proposal samples very quickly approach while for stepsize larger than
, the simulations to the right of the orange symbol, the accepted
percentage approaches as a power law.
To get a sense of why this happens the stepsize is compared to the standard deviation
of the target distribution computed from equation , using the assumed values for
and , gives .
This value is the same order of magnitude of the best performing stepsize determined from simulations.
Comparing the stepsize to the target standard deviation in the large and small limits
provides an interpretation of the results. For small stepsize relative to the target standard
deviation the proposal variance is much smaller then the target variance. Because of this the steps
taken by the proposal Markov Chain are small leading
to a exploration of the target distribution that never goes far from the initial value. The samples
produced will have the proposal distribution since nearly all proposals are accepted.
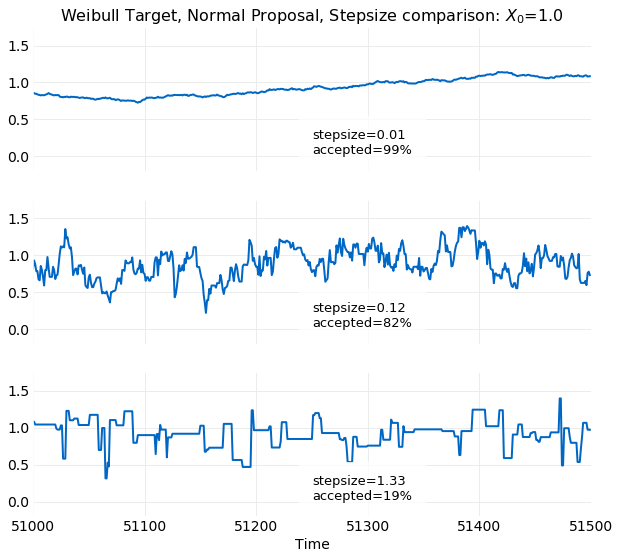
This is seen in the first of the following
plots where time series examples for different stepsize values for the last steps
for a sample simulation are shown. The small variance seen in the first
plot is a consequence of the small stepsize leading to very small deviations from the initial value x0=1. In the
opposite limit where the stepsize becomes large relative to the target standard deviation the steps taken by the proposal
Markov Chain are so large that they are frequently rejected since low probability target events are oversampled. This effect is seen in
last time series plot shown below. There long runs where the series has a constant value are clearly visible. The
best value of stepsize relative to the target standard deviation occurs when they are about the same size. The middle plot
below has the optimal stepsize of and accepted of the proposed
samples. It clearly has a more authentic look than the other two simulations which are at extreme values of the
percentage accepted.
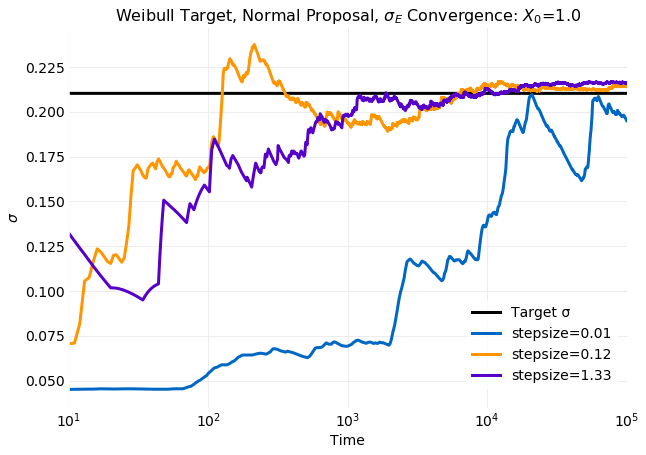
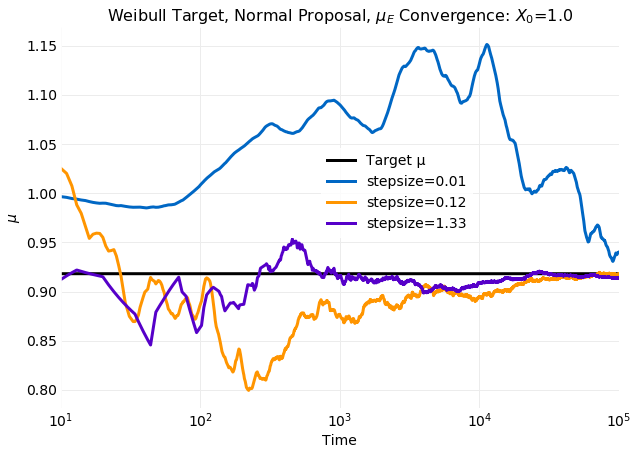
A measure of simulation performance is the rate of convergence of distribution moments computed from
samples to the
target distribution momements. The next two plots show convergence of the cumulative sample mean,
, and standard deviation, , to the target
distribution values computed from
equation for three values of stepsize that compare
simulations at both the
small and large extremes with the optimal stepsize of .
For both
and the small stepsize example is clearly the worst performing. After
time steps there is no indication of convergence. There is no significant difference between the
other two simulations. Both are showing convergence after samples.
A consequence of using a Markov Chain to generate samples is that autocorrelation is built into the model.
This is considered an undesirable artifact since in general independent and identically distributed samples
are desired. It follows that there is a preference for rapid decorrelation of samples. The following plot
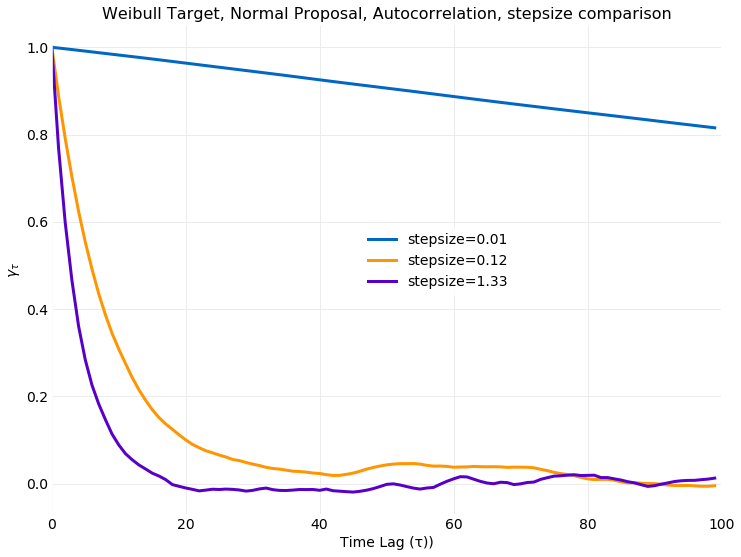
shows the autocorrelation coefficient for the three values of stepsize previously discussed.
The autocorrelation coefficient of a time series, , provides a measure of
similarity or dependence of the series past and future and is defined by,
where and are the time series mean and
standard deviation respectively. Calculation of autocorrelation was discussed in a
previous post.
The small stepsize simulation has a very slowly decaying autocorrelation. For time lags of up to 100
steps it has decayed by only a few precent. This behavior is expected since for small
stepsize the resulting samples are from the proposal Markov Chain, with stochastic
kernel shown in equation , which has an autocorrelation coefficient independent
of given by .
The other simulations have a similar decorrelation rate of time steps,
though for the larger stepsize the decorrelation rate is slightly faster.
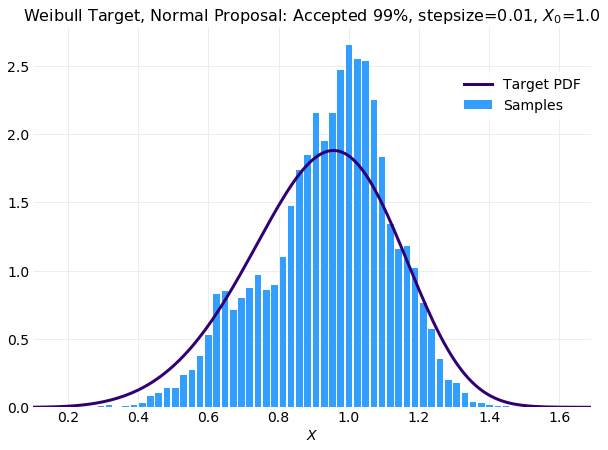
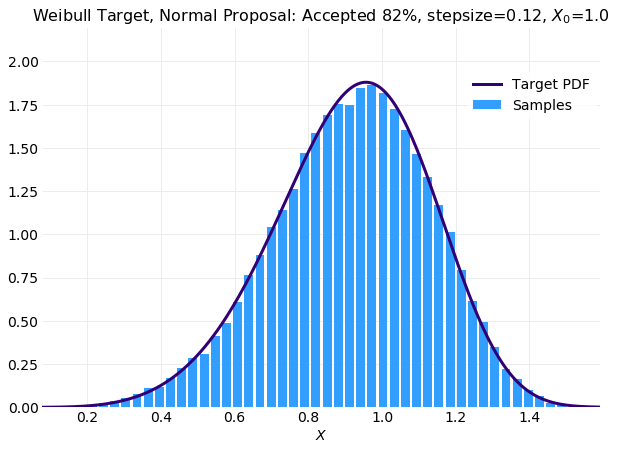
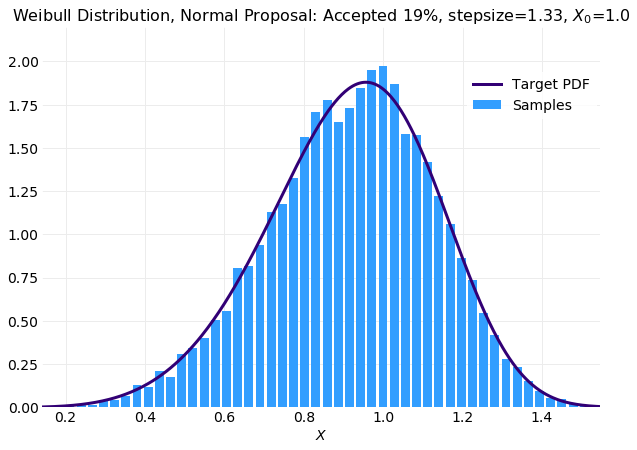
The following three plots compare histograms computed from simulations of samples with the target
distribution from equation for the same stepsize
values used in the previous comparisons. The first plot shows the small stepsize simulation with a very high acceptance rate.
For this case the simulated histogram is not close to reproducing the target distribution. The last plot is the large stepsize simulation
with a very large rejection rate. When compared with optimal stepsize of simulation shown in the middle plot
the larger stepsize simulation is not as smooth but is acceptable. The degraded performance of larger stepsize simulation
will be a consequence of rejection of many more proposal samples leading to long stretches of repeated values. For the
optimal stepsize simulation almost times more samples are available
in the histogram calculation.
In summary a collection of simulations using the Metropolis Hastings Sampling algorithm to sample a target
distribution using a
proposal distribution have been performed that scan the stepsize parameter for a fixed initial value
of x0=1.0 in an effort to determine the best performing stepsize. Best performing was determined by considering
the total percentage of accepted samples, the quality of the generated time series, the convergence of first
and second moments to the known target values, the decorrelation timescale and fit of sample histograms to
the target distribution. The best performing stepsize was found to have a value of
which is near the standard deviation of the target distribution.
For values of stepsize smaller than the best
performing stepsize the performance was inferior on all counts. The number of accepted
proposals was high,
the time series look like the proposal distribution, convergence of moments is slow, samples
remain correlated
over long time scales and the distributions computed from samples do not converge to the target distribution.
When the same comparison is made to simulations with a larger stepsize the results were less conclusive.
Larger values of stepsize accept fewer proposal samples. This causes degradation of the time series since there
are many long runs of repeated values. In comparisons of convergence of distribution moments and autocorrelation
there was no significant differences but calculation of the distribution using histograms on sample data were not
as acceptable since an order of magnitude less data was used in the calculation because of the high rejection percentage.
Burn In
In the previous section simulations were compared that scanned stepsize with x0 fixed. Here
simulations with stepsize fixed that scan x0 are discussed. The further x0 is from the
target distribution mean the further displaced the initial state is from equilibrium so the
expectation is that a longer time is required to reach equilibrium. If
some knowledge of the target mean is available it should be used to minimize this relaxation period.
The time required to reach equilibrium is referred to as burn in. Typically the
burn in period of the simulation is considered and artifact and discarded with the aim of
improving the final result. The expectation then is that the simulation is generating natural
fluctuations about equilibrium.
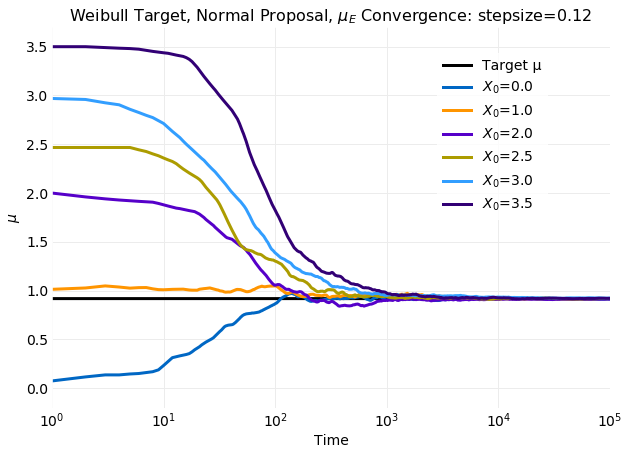
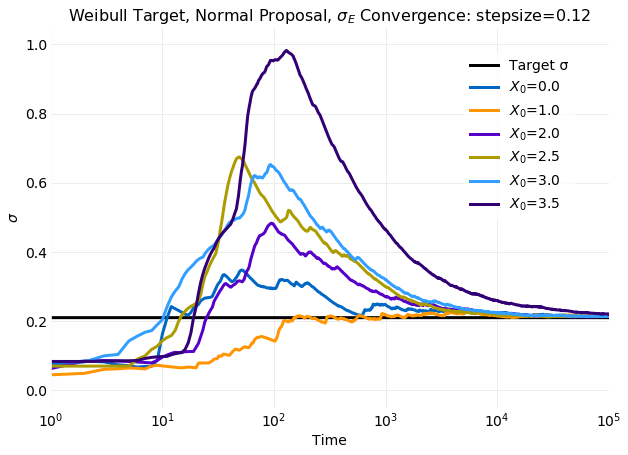
The two plots above compare cumulative first and second moment calculations on simulated samples with
the target distribution values calculated from equation
using and . The obtained
mean and standard deviation are and respectively.
In the plots time to reach equilibrium in seen to increase with increasing displacement of x0 from
. For the simulation at the most extreme value of x0 the time to reach equilibrium
is a factor of longer than the simulation that reached equilibrium first.
For standard deviation the effect is even larger increasing the relaxation time by nearly a factor of
when compared to the fastest relaxation time seen. There is also a very
large spike in the standard deviation that increases with displacement of x0 from the target mean.
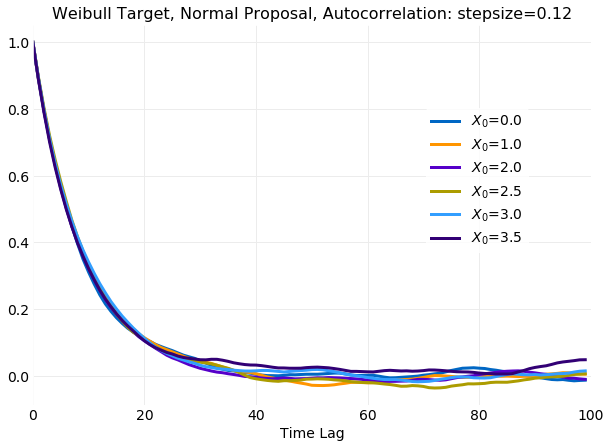
The following plot of the autocorrelation coefficient shows that time for sampled time series to
decorrelate is not impacted by the initial value of x0.
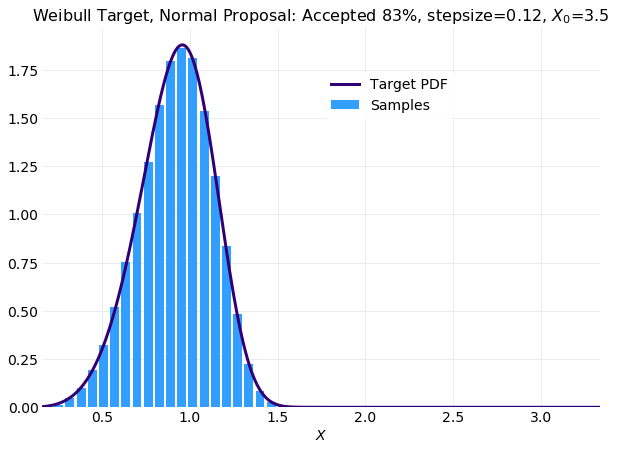
The next plot shows a comparison of the histogram computed from the worst performing simulation
with x0=3.5 with the target distribution. The over representation of large low probability
samples induced by the large displacement of the initial condition is
apparent in the long right tail.
In the next series of plots a burn in period of time steps is assumed
and the data is excluded from calculations. This corresponds to removing
of the samples. The magnitude of the adjustment
to equilibrium is significantly reduced. Within time steps all
simulations for both moments are near their equilibrium values with no significant
difference in the convergence rate. The clear increase in the time of convergence to equilibrium
with displacement of x0 from the equilibrium value seen when all samples are included has been eliminated.
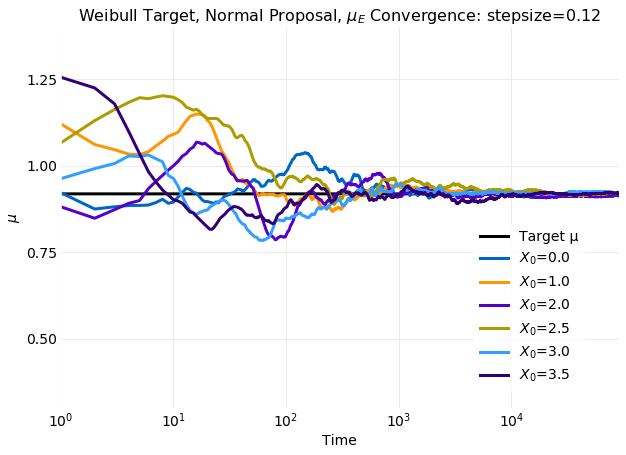
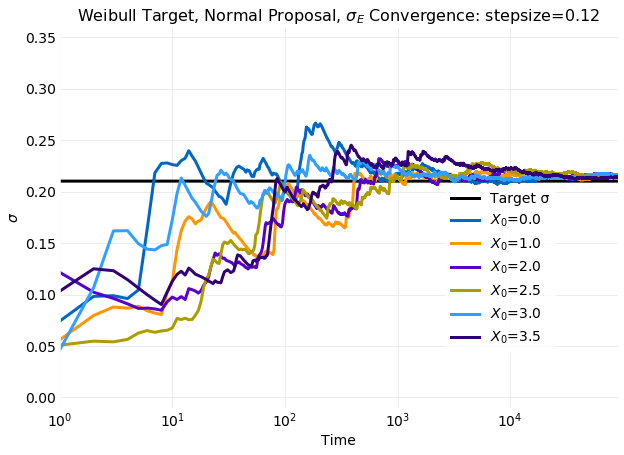
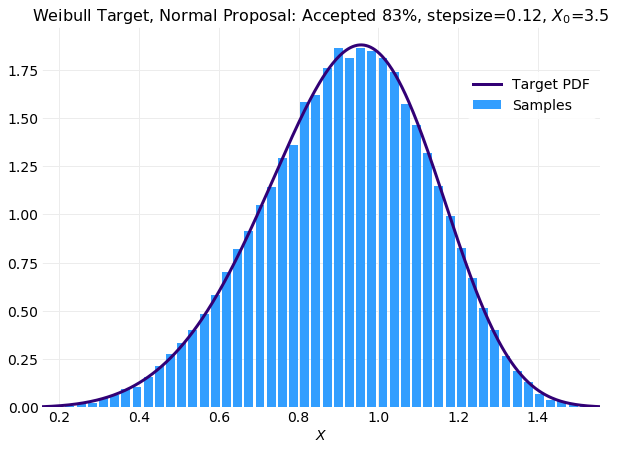
The final plot compares the sample histogram with burn in removed for the simulation with
x0=3.5 to the target distribution. It is much improved from the plot in which burn in was retained.
In fact it is comparable with the same plot obtained for a simulation where x0=1 above.
Thinning
It is desirable that sampling algorithms not introduce correlations between samples since random number generators for a given distribution are expected to produce independent and identically distributed. Since Metropolis Hastings Sampling models generated samples as a Markov Chain, autocorrelation is expected because the proposal stochastic kernel depends on the previously generated sample. Thinning is a method for reducing autocorrelation in sequence of generated samples. It is a simple algorithm that can be understood by considering a time series samples of length . Thinning discards samples that do not satisfy , where is referred to as the thinning interval. Discarding all but equally spaced samples increases the time between the retained samples which can reduce autocorrelation.
The impact of Thinning on the appearance of the time series is illustrated below. The first plot is from the original time series and the others illustrate increasing the thinning interval. The first point in each plot is the same and the plot range is adjusted so that all have samples. A tendency of series values to infrequently change from increasing to decreasing as time increases is an indication of autocorrelation. Comparison of the original series with the thinned series illustrates this. The plot with may have runs of samples with a persistent increasing or decreasing trend which is consistent with decorrelation time of previously demonstrated. For increasing the length of increasing or decreasing trends clearly decreases.
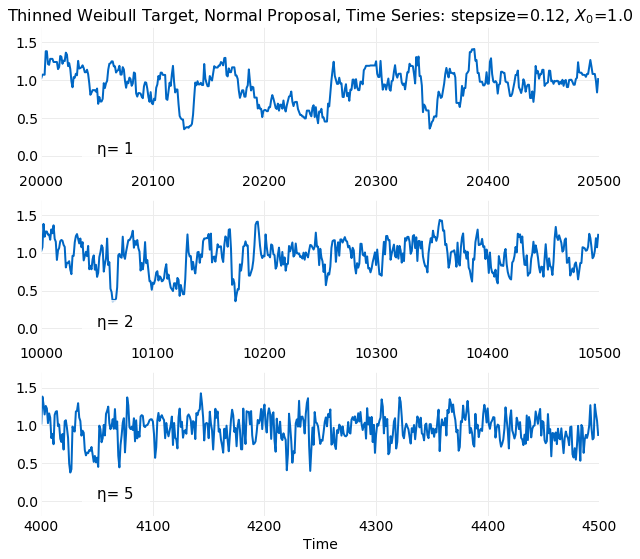
The following plot confirms this intuition. The simulation samples are generated
using Metropolis Hastings with a target
distribution and proposal distribution with x0=1
and the previously determined best performing stepsize=0.12. The burn in period samples
have also been discarded. A value of corresponds
to not discarding any samples. It is seen that the decorrelation time scale decreases rapidly
with most of the reduction occurring by
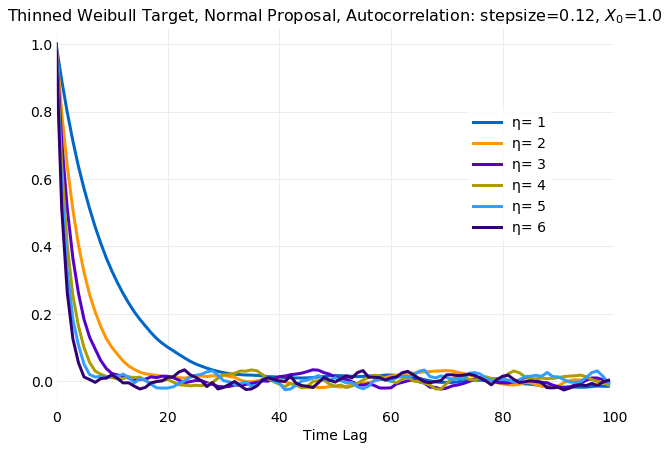
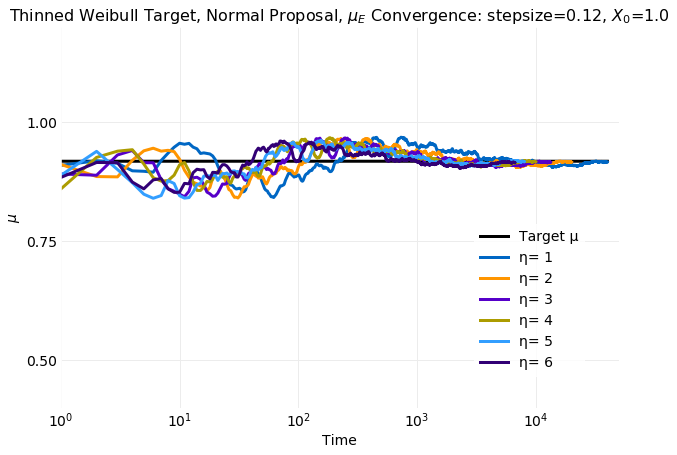
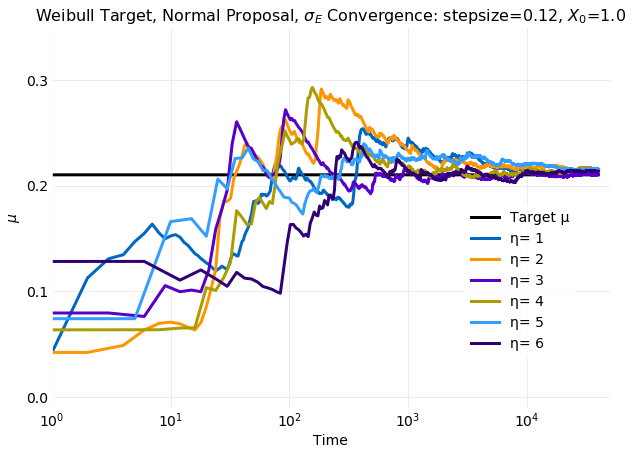
Thinning has no impact on the rate of convergence of first and second moments computed from samples to the target distribution values. This is shown in the following two plots which have convergence rates of samples as seen in the previous section when only the burn in samples were discarded.
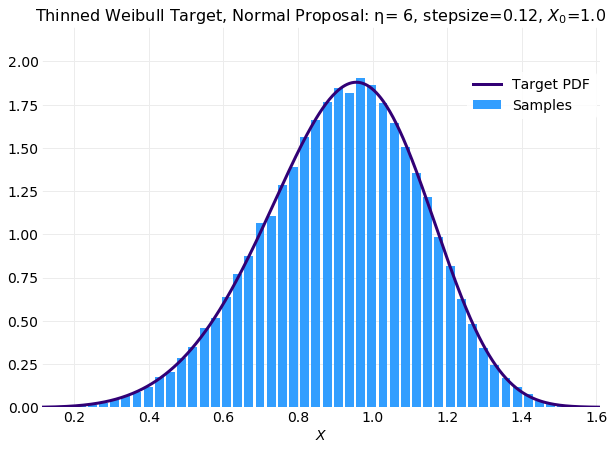
The following two plots compare histograms computed from samples with the target distribution for different values of the thinning interval. The first plot shows the original series and the second the result from thinned samples. The fit of the thinned plot is degraded but this will be due to the smaller number on samples. The original series consists of samples and the thinned series . It follows that if fairly aggressive thinning is performed simulations may need to be run longer to obtain a sufficient set of samples.
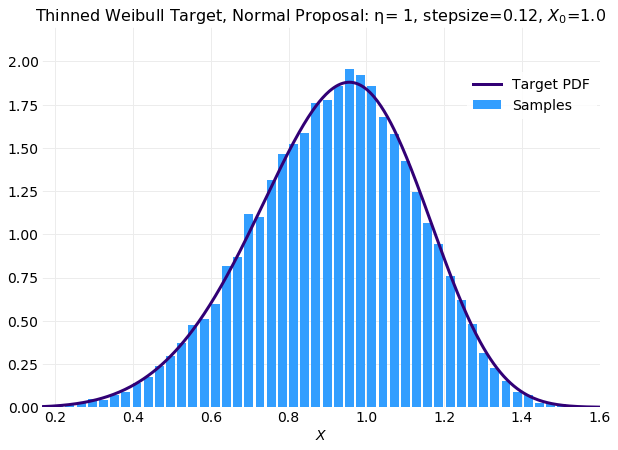
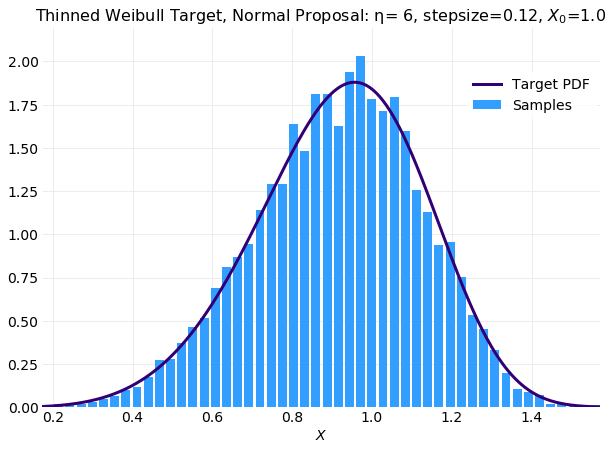
The following plot shows the results of a simulation samples that is comparable with the result obtained without thinning.
Conclusions
The Metropolis Hastings Sampling algorithm provides a general method for generating samples for a known target distribution using an available proposal sampler. The algorithm is similar to Rejection Sampling but instead of discarding rejected proposal samples Metropolis Hastings Sampling replicates the previous sample. It also has a more complicated acceptance function that assumes the generated samples are a Markov Chain. Metropolis Hastings Sampling is simple to implement but the theory describing how it works is more sophisticated than that encountered in both Inverse CDF Sampling and Rejection Sampling.
The theoretical discussion began by deriving the stochastic kernel following from the assumptions introduced by the rejection algorithm, equation . Next, it was shown that if Time Reversal Symmetry were assumed for the stochastic kernel and target distribution, equation , then the target distribution is the equilibrium distribution of the Markov Chain created by the stochastic kernel. Finally, the acceptance function, equation , was derived using Time Reversal Symmetry.
A Python implementation of a Metropolis Hastings Sampler was presented and followed by discussion of an
example using a distribution as target and a
distribution as proposal.
A parameterization of the proposal stochastic kernel using setpsize as the standard deviation
of the proposal distribution was described. The results of a series of simulations that varied stepsize for a fixed initial state, x0, over several orders of magnitude were presented.
It was shown that
the best performing simulations have stepsize that is about the same as the standard deviation
of the proposal distribution. This was followed by simulations that scanned x0 for the
stepsize determined as best. It was shown that the best performing simulations have x0 near
the mean of the target distribution but that if the first samples
of the simulation were discarded x0 can differ significantly from the target mean with no impact.
Autocorrelation of samples is a consequence of using a Markov Chain to model samples and
considered an undesirable artifact since independent identically distributed samples are desired.
Autocorrelation can be removed by Thinning the samples. It was shown that thinning intervals
of about can produce samples with a very short decorrelation time
at the expense of requiring generation of more samples.
The best performing simulations using Metropolis Hastings Sampling have an acceptance rate of about and converge to target values in about time steps. This is the same performance obtained using Rejection Sampling with a proposal distribution. The advantage offered by Metropolis Hastings Sampling is that it has a single arbitrary parameter. Rejection sampling has two arbitrary parameters that can significantly impact performance for small changes. It follows that Metropolis Hastings Sampling can be considered more robust.